
Big Data & Leadership Strategies For Enabling Quality By Design
By Peiyi Ko, Ph.D., and Peter Calcott, Ph.D.

The biopharmaceutical industry has unique commercial risks, including complex molecule products, costly supply chain infrastructure that takes a long time to construct, and raw material variations’ impact on process quality and yields. The key to managing this myriad of risks is thought to be a systematic and cross-functional method involving all levels of the company while continually improving assessments and plans to mitigate risks; specifically, sharing goals or quality criteria between R&D and manufacturing, increasing production efficiency, constructing facilities that allow production flexibility, and preventing supply disruption with better visibility into and control over both immediate suppliers and sub-tier suppliers.1 As it becomes easier and cheaper to set up an infrastructure to generate, collect, and analyze large amounts of data, midsize and large organizations see the need to leverage data.
However, ever-increasing amounts of data generated throughout the product life cycle can be hard to utilize to the organization’s advantage because of silos, misalignment, and complexity. In the previous article, we discussed the challenges and importance of data-driven approaches for improving knowledge management and risk management to enable quality by design (QbD).2 In this article, we will dive deeper into data management strategies (the technical perspective) and leadership principles (the human perspective) that address these fundamental challenges.
Data Management Strategy For Operational Excellence & Quality-Based Decision Making
According to a recent market research survey by Pharmaceutical Manufacturing, manual processes in deviation/incident management, corrective actions and preventative actions (CAPAs), and risk management are still the norm in the industry, permitting human errors and inefficiency. Poor integration with other business processes still limits commercially available quality management system software.3 This is within the organization as well as the supply chain, thus impeding supplier quality management and proactive risk management that could prevent issues leading to a recall. In the pursuit of centralization of information and standardization of processes, current trends in Big Data offer some ideas.
The main purpose of implementing Big Data is to achieve speed, processing power, storage capacity, and ease of maintenance by efficiently mining the information hidden in all data. Heisterberg and Verma propose that organizations can integrate various data sources and associated technologies to form a digital business value chain that enables internal innovation via collaboration and leverages external trading partners’ capabilities; this ability to anticipate challenges and opportunities before they occur is “business agility.”4 Cloud computing and/or Big Data approaches offer the foundation for organizations to develop and manage knowledge internally to facilitate collaboration. Once organizations achieve Big Data processing by efficiently utilizing computing powers of the infrastructure with cost-effectiveness, they have the potential to gain insights about their customers, market, industry trends, and changing competitive environment to make decisions such as service and product design, development, and production. These findings help not only in implementation of QbD but will change targets as companies refine true customer needs. However, our previous survey findings suggested companies struggle with where to start applying Big Data for knowledge management and how people can share and collaborate.5 Therefore, we propose three general recommendations for Big Data deployment.
1. Focus On Delivering Business Value & Engaging Stakeholders
Big Data projects start with defining business mission requirements and use cases, first asking “How can Big Data help?” As part of the agenda-setting process, decision makers need to review the core process and determine the impact of changes. A good starting point for constructing data stories that inspire engagement and commitment to drive initiatives forward is complexity analysis, which maps and quantifies the financial impact of complexity within an organization.6 The journey should be iterative, starting with a specific case by augmenting current IT investments or utilizing off-the-shelf services, then expanding to adjacent use cases by building out a more robust and unified set of core technical capabilities.
A Big Data project attempts to bring these elements under one roof for the ease of information access. General phases of implementation go from pilot to departmental analytics to enterprise analytics to Big Data analytics. In an ideal world, an enterprise reaps the benefits of Big Data with clear business drivers, agile systems, sustainable data processes, and people engagement that together produce focused master data and data quality across sources. Strategy, infrastructure, governance, and a road map for a Big Data information plan along with a holistic approach following these key items are also recommended: (1) Identify data and content that are vital to its mission, (2) identify how, when, where, and to whom information should be made available, (3) determine appropriate data management, governance, and security practices, and (4) identify and prioritize the information projects that deliver the most value.8
2. Start Small To “Nail It Before Scale It”
There is certainly more data available at lower costs for predicting market, product, and customer trends, almost enough to overwhelm. Still, there’s a common framework for a Big Data approach to data management. At the core, Big Data aims to establish a process to parse large data sets from multiple sources to produce near-real-time or real-time information. However, Big Data deployments are unique to the individual company’s business imperatives and use cases. Before achieving an integrated system that is streamlined for the intended purpose (i.e., unifying the data around the customer or the product to gain insights about responding to uncertainties and changes), it is also wise to take an intermediate step to be “intelligently lean” (i.e., strategic elimination of steps that do not add value) and learn from the smaller scale of experimentation. For example, effective supply chain management relies partially on having flexible manufacturing capability. One trend is to establish intelligent machining. However, it is suggested that overfitting facilities with heavy machinery makes them less able to respond to changing markets; for this purpose, the first step to set up AI for an automated production line would be feature selection (i.e., figure out what variables to incorporate into the machine learning model).9
Technologies such as Industrial Internet of Things (IIoT) and remote monitoring advances in manufacturing, data generated by smart meters, manufacturing sensors, and equipment logs form large volumes of semi-structured semantic data. That data typically is not associated with applications and requires different analysis than traditional structured data in a relational database management system. This requires changing from traditional data warehousing approaches to Big Data analytics. Both approaches aim to use data to inform business decisions, yet they differ in how data is acquired, organized, and analyzed. The Big Data approach has three main elements: (1) distributed storage and processing such as in a cloud or at a distal/original location to handle a large volume of data, (2) a variety of data types that could be stored in a NoSQL database before being retrieved for analysis, and (3) high-velocity inputs for near-real-time analytics. In contrast, traditional data warehousing usually hosts clean, quality, and structured operational data from legacy systems.
One data warehousing methodology is top-down (i.e., normalized enterprise data model), which is complex, expensive, time-consuming, and prone to failure but can also result in an integrated, scalable warehouse if successful. The other is bottom-up (i.e., dimensional data marts), which is most common, serves as proof-of-concept for data warehousing, can perpetuate a “silos of information” problem, and requires an overall integration plan. Both are the norms adopted by businesses yet are not agile compared to the Big Data approach. The new “logical data warehouse” requires realignment of practices and a hybrid architecture of repositories and services and will demand the rethinking of deployment infrastructures.8
3. Adopt Design Principles For “Humanizing” Big Data To Manage Complexity & Better Deliver The Data Story
Common Big Data workflows involve handoffs and delays; this could be reduced by empowering “data artisans” to perform all Big Data analytics except for defining the business question and making business decisions. The design principles for creating solutions for insights include: (1) ingest and integrate data from anywhere, (2) seek patterns by fusing qualitative structured data with important contextual information from unstructured data, (3) make insight widely available across the enterprise, especially at the point of decision, and (4) reuse analytical IP created by a data artisan, allowing decision makers to adapt and build on the data to gain focus as the data story extends.10 With these principles embedded in the process and deployment program, the effectiveness and impact could be maximized. One example data story: The product and process knowledge from development through the commercial life of the product up to and including product discontinuation is vast. The International Society for Pharmaceutical Engineering (ISPE) reported two large-scope quality metrics pilot programs found the efforts of data collection needed for quality metrics reporting (especially product-based) can be daunting. One initiative might explore reduction of deviation recurrence rate through more effective investigation, root cause analysis, and CAPA driving down COGS.
To further add to the complexity of the digital value chain, trends in patient-centric medicine expand the scope of consideration to individual patients, which will drastically change the mode of manufacturing and delivery, hence requiring data management.11 Upcoming serialization and end-to-end track-and-trace implementation deadlines will fill in the data gap of a product from the manufacturer to a specific patient. Technologies can be combined in different ways to provide unique solutions to Big Data implementations in this scenario. Regardless, sound data governance practices such as master data management (MDM) to maintain a “single source of truth” and utilizing meta data to effectively index data contents are important to the maintenance of the program.
It is also essential to have data management processes that consider standardization and design for ease of traceability, accountability, and organization, especially at this scale. Companies need to consider both inputs and outputs of the process/technology system in achieving analytics goals. To ensure data quality (inputs) and benefits to decision making (outputs), designing for integrated workflow, applying standardization of data and report formats, and establishing good data governance practice are all essential. Disciplined data checks and maintenance (data integrity) are necessary to ensure gathering quality information with minimal efforts (and troubles) down the road. For example, “dirty data” (e.g., spelling discrepancies, multiple account numbers, address variations in customer data, missing data, free-form fields) that leads to erroneous analytic results is a common problem. Creating a clean master list can be a formidable challenge, yet there are many benefits to a company’s bottom line. And this approach eventually manifests as patient-centric data, where the interplay between critical quality attributes (CQAs) and critical process parameters (CPPs) could even be contextualized for a single patient taking a single product.
Leaders and project managers could utilize a “data storyboard” for formulating and communicating the vision, objectives, and approaches for projects. Of course, the story will not be set in stone — instead, it will evolve as the transformation takes place. The diagram below illustrates an example of going through the data life cycle to harness insights from available internal and external data.
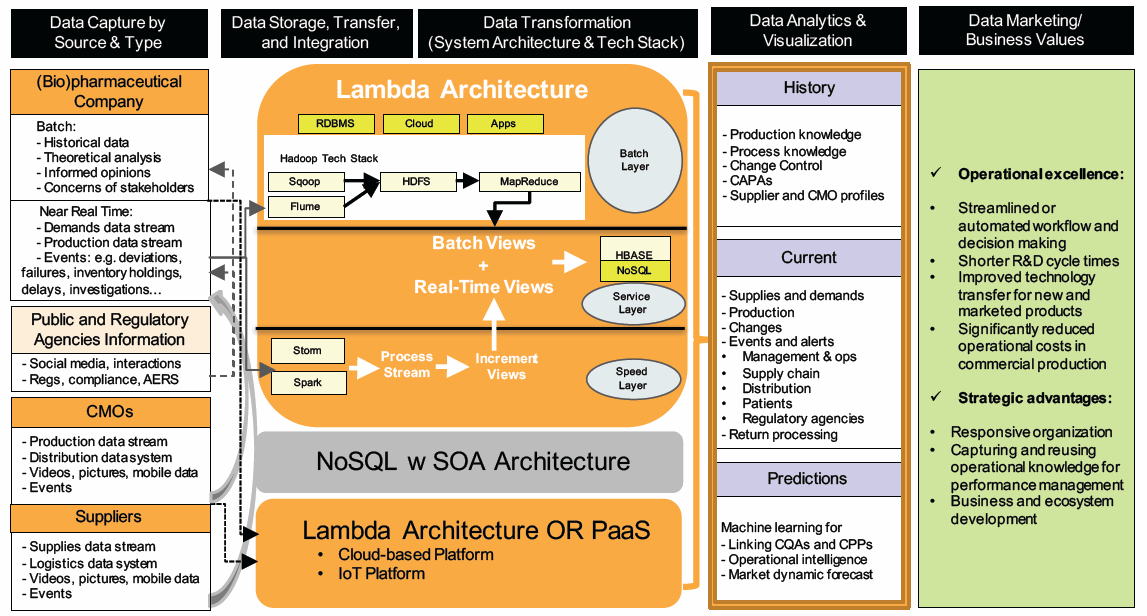
© KoCreation Design 2017
Managing Silos & Complexity For Guidance Implementation
Aside from technology implementation, successful operational transformations often require significant cultural change. In organizational development practice, leadership addresses complexity by creating direction, alignment, and commitment. Some of the leadership lessons on quality learned from the industry over the years could be reflected in a recent article discussing Edward Deming’s 14 points for management.12 It comes back to creating ownership of the whole project to which everybody contributes.
The guidance expects internal communication has established processes that ensure the flow of appropriate information among all levels of the company and ensure appropriate and timely escalation of certain product quality and quality system issues. However, silos created by disparate systems and perpetuated by culture can prohibit effective knowledge management. corporate strategy is to develop operating levers that not only serve as the building blocks for a new operating model but also enable interdisciplinary “critical teams” to help develop organizational responsiveness and insights; these levers range from strategy, organizational structure, and processes/systems/tools, to skills and culture.13 The critical teams situated at the intersections in the organizations that are responsible for evidence generation and management (R&D, pharmacovigilance, health outcomes research), connected delivery (manufacturing and distribution), and customer management (sales and marketing, key account management) articulate value proposition, foster cross-functional collaboration, proactively share customer feedback, and prepare and shape the external environment. They need to be early technology adopters and capable of translating data/information into business insights and strategies.
To achieve the maximum impact of these efforts, there is also a need to facilitate the three fundamental mechanisms that Morten Hansen, author and researcher at UC Berkeley, proposed for a leader to unify groups to collaborate: (1) craft a central unifying goal that is easy to describe and is compelling, (2) create and demonstrate a core value of teamwork, including demanding contributions both within individual units and across the company, and (3) encourage collaboration through formation of nimble networks.14 For integrated initiative to work, players within the organization must give up ownership of the data they generate for the better good of the company versus their own careers.
Conceptually, there are several design principles for a complex system to work well for people. Examples include: (1) design for understanding by including appropriate structure to aid human comprehension and memory, (2) facilitate user learning as well as development of abilities and skills to understand and use the system, and (3) design a tolerant system with social design for confidence and reassurance.15 Work domain analysis, participatory design, and physical ergonomics are methods that intend to “support identification and exploration of design alternatives to meet the requirements revealed by analyses of opportunity space and context of use.”16 They are mainly applied in the design phase yet also when defining the context of use and evaluating the design outcome. Findings from these inquiries can be captured in a good business requirement document (BRD). This could tackle some common complexity symptoms such as unnecessarily lengthy SOPs, convoluted processes with redundancies, and adding third signatures.
At a higher level, we ask how companies navigate these socio-technical system complexities, get to know the unknown sooner, and respond effectively faster. One approach to analyzing a complex socio-technical system is cognitive work analysis (CWA), which depicts the functional, situational, activity, decision, strategic, social, and competency constraints to help create not only an analytical but a visual representation of how everything works together, as illustrated by Stanton and Bessell.17 With inputs from users, project managers, and technical experts, elements of CWA could build a comprehensive current state of system/process/social constraints to help articulate system needs and goals, the processes required to meet them, and the key operational and environmental factors that influence decisions and possible outcomes (e.g., risks, assumptions, constraints, and impacts).
Conclusion
To summarize our findings, companies need to ask the following questions in this type of project:
- Do we have the right amount of knowledge to make effective changes?
- Do we have appropriate systems in place to use the knowledge for change?
- Is the knowledge in the right place at the right time to facilitate change?
- Is the culture ripe for change?
This is true for gap assessments and remediation, responses to audits and inspections, continuous improvement, and “mega changes.” Technology, processes, and people are equally important to achieve effective knowledge management and data-driven risk assessment for QbD (and beyond).
References:
- GE Healthcare Life Sciences. (2017). Managing Risk in Biomanufacturing. Retrieved from Bioprocess Online: https://www.bioprocessonline.com/doc/managing-risk-in-biomanufacturing-0001
- Ko, P., & Calcott, P. (2017). Rethinking Knowledge Management & Data-Driven Risk Management For Quality By Design. Retrieved from Pharmaceutical Online: https://www.pharmaceuticalonline.com/doc/rethinking-knowledge-management-data-driven-risk-management-for-quality-by-design-0001
- Langhauser, K. (2017). Quality, Compliance and Risk Management: Where We Stand. Retrieved from Pharmaceutical Manufacturing: http://www.pharmamanufacturing.com/articles/2017/quality-compliance-and-risk-management-where-we-stand/
- Heisterberg, R., & Verma, A. (2014). Creating Business Agility: How Convergence of Cloud, Social, Mobile, Video, and Big Data Enables Competitive Advantage. Hoboken, New Jersey, USA: John Wiley & Sons, Inc.
- Calcott, P., & Ko, P. (2017). Measuring The Impact Of Recent Regulatory Guidances On Pharma Quality Systems. Retrieved from https://www.pharmaceuticalonline.com/doc/measuring-the-impact-of-recent-regulatory-guidances-on-pharma-quality-systems-0001
- George, M. L., & Wilson, S. A. (2004). Conquering complexity in your business. New York, New York, US: McGraw-Hill.
- Biovia. (2017). Critical Opportunity For Pharmaceutical And Process Understanding. Retrieved from Pharmaceutical Online: https://www.pharmaceuticalonline.com/doc/critical-opportunity-for-pharmaceutical-and-process-understanding-0001
- Federal Big Data Commission. (2012). Demystifying Big Data: A practical guide to transforming the business of government. TechAmerica Foundation.
- Torrone, D. (2017). Pharma’s Great Automation Migration. Retrieved from Pharmaceutical Manufacturing: http://www.pharmamanufacturing.com/articles/2017/pharmas-great-automation-migration/
- Alteryx. (2015). Humanizing big data: A white paper from CITO research. Retrieved from http://www.dlt.com/sites/default/files/sr/brand/dlt/PDFs/Humanizing-Big-Data.pdf
- Kemppainen, P., & Liikkanen, S. (2017). Pharma Digitalisation: Challenges and opportunities in transforming the pharma industry. Retrieved from European Pharmaceutical Reviews: https://www.europeanpharmaceuticalreview.com/news/51733/pharma-digitalisation-challenges/?utm_medium=email&utm_campaign=EPR%20-%20Newsletter%2022%202017&utm_content=EPR%20-%20Newsletter%2022%202017%20CID_90914ef38c2cbe98eef6c4809e1e0f2e&utm_source=Email%2
- Vinther, A., & Schillinger, C. (2017). Deming, Finally! Retrieved from We need social: http://weneedsocial.com/blog/2017/6/13/deming-finally
- Pisani, J., & Lee, M. (2017). A critical makeover for pharmaceutical companies: Overcoming industry obstacles with a cross-functional strategy. Retrieved from https://www.strategyand.pwc.com/reports/critical-makeover-pharmaceutical-companies
- Hansen, M. T. (2009). Collaboration: How leaders Avoid the traps, Create Unity, and Reap Big Results. Boston, Massachusetts, US: Harvard Business School Publishing.
- Norman, D. (2010). Living with Complexity. Cambridge, Mass, US: MIT Press.
- National Research Council, Division of Behavioral and Social Sciences and Education, Committee on Human Factors, Committee on Human-System Design Support for Changing Technology. (2007). Human-System Integration in the System Development Process: A New Look. (R. W. Mavor, Ed.) Washington, D.C.: The National Academies Press. https://doi.org/10.17226/11893
- Stanton, N. A., & Bessell, K. (2014). How a submarine returns to periscope depth: Analysing complex socio-technical systems using Cognitive Work Analysis. Retrieved from: https://www.ncbi.nlm.nih.gov/pubmed/23702259
Appendix:
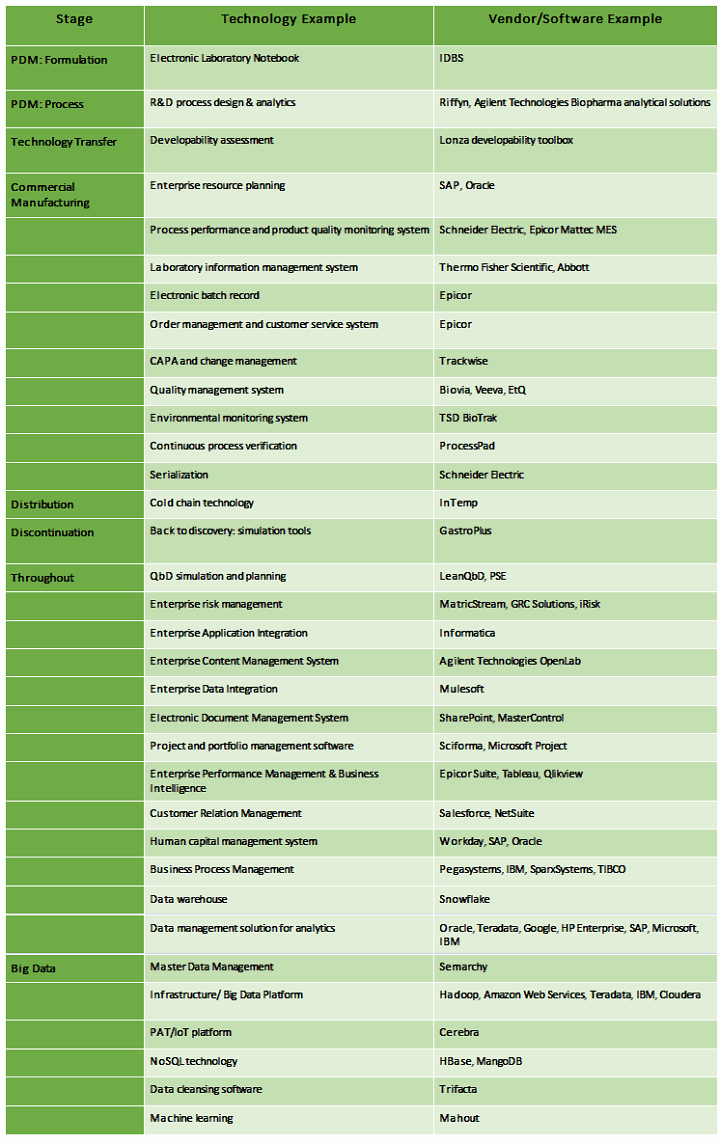
Below is a small sample of technology that could be part of QbD knowledge creation and management. (Disclaimer: This list is not exhaustive nor meant to be recommendations.)
About The Authors:
 Peiyi Ko, Ph.D., founder of KoCreation Design, creates opportunities for positive changes and innovation through human-system interaction research and human-centered design. She has guest lectured at universities and led workshops. She is also a Certified Professional Ergonomist and collaborates with the Interdisciplinary Center for Healthy Workplaces at UC Berkeley as a consulting expert. She has provided human factors/ergonomics consulting as well as software usability analyses and design recommendations for operational improvements at the Lawrence Berkeley National Laboratory and at BSI EHS Services and Solutions. She obtained her Ph.D. from UC Berkeley in 2012 with additional training from two interdisciplinary certificate programs there: Engineering, Business & Sustainability and Management of Technology. You can reach her at info@kocreationdesign.com.
Peiyi Ko, Ph.D., founder of KoCreation Design, creates opportunities for positive changes and innovation through human-system interaction research and human-centered design. She has guest lectured at universities and led workshops. She is also a Certified Professional Ergonomist and collaborates with the Interdisciplinary Center for Healthy Workplaces at UC Berkeley as a consulting expert. She has provided human factors/ergonomics consulting as well as software usability analyses and design recommendations for operational improvements at the Lawrence Berkeley National Laboratory and at BSI EHS Services and Solutions. She obtained her Ph.D. from UC Berkeley in 2012 with additional training from two interdisciplinary certificate programs there: Engineering, Business & Sustainability and Management of Technology. You can reach her at info@kocreationdesign.com.
 Peter H. Calcott, Ph.D., is president and CEO of Calcott Consulting LLC, which is focused on delivering solutions to pharmaceutical and biotechnology companies in the areas of corporate strategy, supply chain, quality, clinical development, regulatory affairs, corporate compliance, and enterprise e-solutions. He is also an academic program developer for the University of California, Berkeley in biotechnology and pharmaceutics postgraduate programs. Previously, he was executive VP at PDL BioPharma, where he was responsible for development and implementation of quality and compliance strategy across the corporation. He has held numerous positions in quality and compliance, research and development, regulatory affairs, process development, and manufacturing at pharmaceutical companies including Chiron, Immunex, SmithKline Beecham, and Bayer. He has successfully licensed products in the biologics, drugs, and device sectors on all six continents. Dr. Calcott holds a doctorate in microbial physiology and biochemistry from the University of Sussex in England. You can reach him at peterc@calcott-consulting.com.
Peter H. Calcott, Ph.D., is president and CEO of Calcott Consulting LLC, which is focused on delivering solutions to pharmaceutical and biotechnology companies in the areas of corporate strategy, supply chain, quality, clinical development, regulatory affairs, corporate compliance, and enterprise e-solutions. He is also an academic program developer for the University of California, Berkeley in biotechnology and pharmaceutics postgraduate programs. Previously, he was executive VP at PDL BioPharma, where he was responsible for development and implementation of quality and compliance strategy across the corporation. He has held numerous positions in quality and compliance, research and development, regulatory affairs, process development, and manufacturing at pharmaceutical companies including Chiron, Immunex, SmithKline Beecham, and Bayer. He has successfully licensed products in the biologics, drugs, and device sectors on all six continents. Dr. Calcott holds a doctorate in microbial physiology and biochemistry from the University of Sussex in England. You can reach him at peterc@calcott-consulting.com.