
How Amgen Uses AI Tools To Improve Manufacturing Deviation Investigations

Amgen is piloting a process using artificial intelligence (AI) that has the potential to greatly enhance its ability to trend and find patterns in manufacturing deviations and to prevent their recurrence. The AI tool will replace a manual, labor-intensive process with one that can look across large data sets and find correlations between obscure signals and events which the previous system could have missed.
In creating the AI tool, the team used agile software development. Agile development is an iterative approach under which requirements and solutions evolve through the collaborative effort of cross-functional teams and their end users. It involves an incremental development strategy, meaning each successive version of the product is usable and each builds upon the previous version by adding user-visible functionality.
Because the deviation reports — which Amgen calls non-conformance (NC) reports — are documents containing mostly text, the project team decided to employ an AI tool called natural language processing (NLP) to examine them. NLP provides a way for computers to analyze, understand, and derive meaning from human language, including not only words but also concepts and how they are linked together to create meaning.
At the second Xavier Health AI Summit in August 2018 in Cincinnati, Ohio, Amgen Quality Data Sciences Executive Director Dan Weese and Director Mark DiMartino presented the strategy, approaches, and lessons learned from their implementation of AI tools in Amgen’s quality processes, with a specific focus on the NLP project used to analyze and trend manufacturing NCs. (A review of the first Xavier AI Summit a year earlier is available here.)
Using Data Science In Quality Operations
Weese provided an overview of the role data science plays in Amgen’s quality operations. He noted that as a large company manufacturing, purifying, and packaging biotech drugs, a huge amount of diverse data is generated, not all of which is digitized.
The focus of his team’s efforts, Weese said, is the application of data science specifically in quality operations, using a data science process (see figure below). The process begins with a question, after which the team gets the data; explores, models, and visualizes it; and then interprets it for presentation to management.
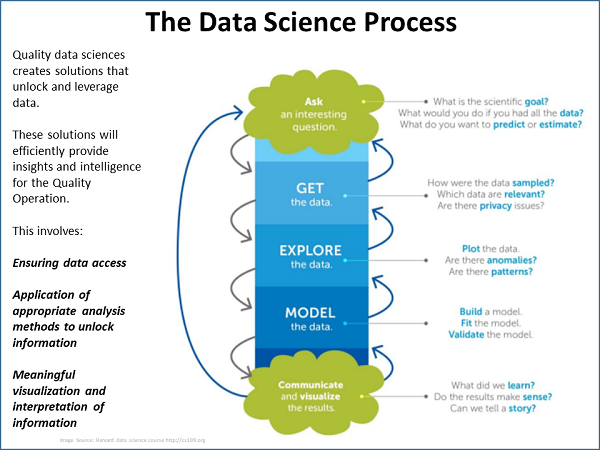
An important component of the process is the creation of a “data lake.” A data lake is a combination of all relevant data, including raw data and transformed data, which is used for various tasks including reporting, visualization, analytics, and machine learning. The data lake can include structured data from relational databases; semi-structured data such as CSV files; unstructured data such as emails, documents, and PDFs; and even binary data.
Weese characterized the data lake as a core technology platform needed to advance data management and analytics capabilities across functions. “We have to have the ability for people to easily input data and get data.”
He noted the data lake could be large, and the company needs the right tools to analyze and visualize it. “We have a race at the company right now to see whether [software platforms] tableau or Spotfire are the best tools to visualize data. Then we need to be able to apply some of the data science tools such as jupyter, python, and RStudio. These are free and downloadable. So this is not a discussion about the coding — it is about how we use it to get business results.”
The next step is finding people who will access, visualize, and analyze the data to unlock value. Those people need “the knowledge of a subject matter expert [SME], the insight of a mathematician, and the discipline of a computer scientist,” Weese said. “Who has all of those skills combined? Probably no one. So we have to work with these different skill sets and people.”
Regarding the role of data scientists in quality, he said the company believes quality system vigilance provides opportunities for applying data science to core quality function responsibilities, as outlined in the FDA’s 2006 guidance on quality systems. Included in the quality system recommendations from the FDA is “continually monitoring trends and improving systems. This can be achieved by monitoring data and information, identifying and resolving problems, and anticipating and preventing problems.”
Weese presented eight areas Amgen is exploring for attention by data scientists (see figure below).
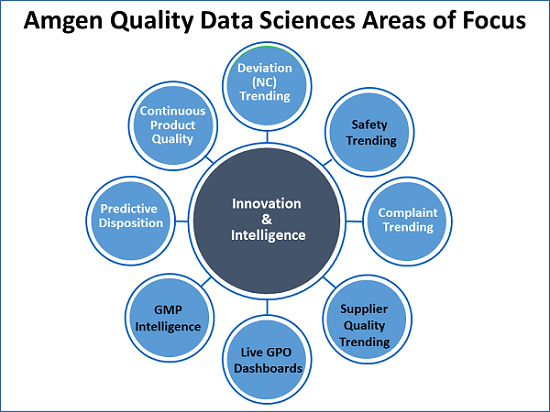
Beginning at the top of the illustration and moving clockwise, Weese began with a brief discussion of trending NCs. “Finding weak signals hidden in deviations is difficult. We can do simple things like Pareto charts, bucketing, and statistical process control charting.”
“In our case, quality owns environmental health and safety. There are a lot of safety incidents. Maybe we can use AI there. We need to keep track of and trend complaints. Then there are supplier quality trending and dashboards of metrics for our process owners. GMP intelligence — that is, can we keep an eye on GMP warning letters and form 483s from agencies and find out what is trending? Predictive disposition — can we predict when we will be ready to disposition any one lot? Continuous product quality, which Xavier has a work stream on, gets into real-time release, which companies like us are very interested in.”
In addition to the continuous product quality work stream, Xavier also has a team of FDA officials and industry professionals that has taken a major step toward forging the use of AI by providing a Good Machine Learning Practices (GmLP) document for the evaluation and use of continuously learning systems.
The Current NC Trending Process Is Manual
DiMartino explained that the purpose of an NC system is to capture errors or deviations, understand the impact on the product and process, investigate to find a root cause, and fix the root cause in order to prevent recurrence. He pointed to the FDA 2006 guidance on quality systems as well as ISO 9001 and ISO 13485, which indicate such a process is needed for both drug and device manufacturing.
“At Amgen, we do not investigate all of our NCs,” DiMartino said. “We rank them based on risk. If they are low risk, we do not necessarily investigate them. But we track them to be sure we do not see recurrence.”
While the goal of the process is finding and correcting root cause, not all root cause investigations are effective. However, a trending process can aid in the investigations by connecting like occurrences the investigator may not have seen.
DiMartino shared a graphic that outlines Amgen’s current NC trending process, which he characterized as robust. It involves the use of control charts and Pareto charts, with monthly and quarterly activities (see figure below).
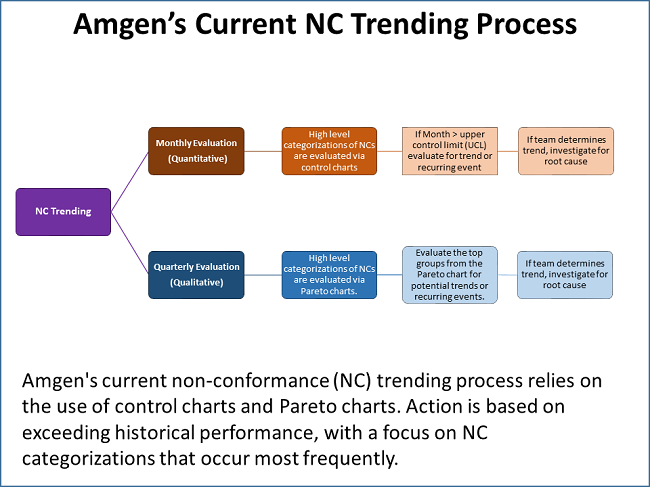
While robust, the trending program does have weaknesses, DiMartino said. “One of the things I have been asked to defend in inspections is, ‘If you are using a control chart, you are setting a baseline and evaluating against an increase relative to that baseline. In doing so, you are accepting there is a baseline level of deviations that is acceptable.’ It is hard to argue against that not being the best approach.”
The NC categorizations are performed using a drop-down menu. While that ensures consistency as opposed to using free form text, the menu selections are based on one or two people’s impressions of what the actual deviation was. This introduces some level of bias and leads to analyses in a silo, such that “weak signals across categories will most likely be missed,” DiMartino pointed out.
He also introduced the topic of “arbitrary influence,” which is illustrated by the use of monthly and quarterly timelines. While useful for planning and scheduling, looking at NCs monthly and quarterly could miss correlations that do not fall within the month or the quarter.
As a first step in beefing up the process, one-sentence descriptions of the NCs were extracted and examined manually for commonalities, which were then reported to functional area leads. However, the flaw with this process is it is labor-intensive and requires judgment at the initial step, which introduces the potential for bias.
Designing And Piloting A New Process
A project team was formed to look for a system algorithm that could replicate and perhaps improve upon the manual process. The goal was to think big but start small and build a product that could be deployed across the manufacturing network. Using an agile development approach and NLP tools, the team developed a consistent algorithm that was able to reasonably replicate the manual process.
DiMartino described NLP as an AI technology that turns text into numbers, which can be read by a computer and used to identify similar records. Each record has a series of numbers associated with it that can be analyzed to create similarity scores.
The records can then be clustered together. Those clusters can then be given to an SME, who can decide if there is trending and if action should be taken. Feedback can then be given to the algorithm, which can be adjusted.
In addition, the tool “takes away the bias of the categorization because it is based on the actual description of the event. It takes away the arbitrary endpoints because it allows looking across longer time frames, taking away the monthly or quarterly component. It updates every day an NC is initiated,” he explained.
The tool also enables exploration of “weak signals” — unstructured, fragmented, or incomplete pieces of data that would rarely be found by human analysis, but that combined could show trends or point to more systemic issues. In the future, by looking at the full text of long descriptions, a more sophisticated NLP algorithm could use topical clustering rather than just text similarity and surpass the current trending and analysis capability.
“If you think about clustering based on like words, what if there are language or context differences in the words — for example, the spellings?” DiMartino asked. “There is a lot of time and effort behind our efforts to create libraries, ontologies, and so on. A big part of this is developing and managing those.”
According to an IBM Community blog on language processing, an ontology is “a description of things that exist and how they relate to each other.” Ontologies are used to aid in the classification of entities and the modeling of relationships between those entities. Ontology-driven NLP involves the use of a semantic model to understand what exists in the unstructured data.
“What we would like to get to is real-time predictive models, and not just for NCs,” DiMartino said. “I would like to be able to predict the outcome of a manufacturing operation based upon different factors that may or may not lead to an NC. This is our first step at building some knowledge of how to take some of that data to feed into a more predictive model. Eventually, we would like to connect it to lots of different data sources and get a more holistic view of product quality in our operations.”
Q&A Focuses On GMP Documentation Aspects
The Q&A session after the Amgen presentation focused on what documentation surrounding this process should conform to GMPs, how the NLP process compares to the manual one, and the cost of investment versus the benefit derived.
An audience member asked the presenters to discuss the company’s validation strategy regarding GMP documentation.
DiMartino responded, “We have deployed this in a production environment. It is a qualified environment, so we know our data access is validated. The transition of the data from one step to the next is all covered.”
He noted the algorithm used for the application is “traceable and repeatable. It is pretty simple math. We have an approach to validate it. What we in the network are having discussions about is how strict the validation has to be.”
Weese said, “The data lake itself is validated. We are pulling from there, and we are certain the data in the data lake from our core systems are correct. As Mark mentioned, we are augmenting humans. How can it be worse than sitting around a table reading all these NCs?”
FDA Center for Devices and Radiological Health (CDRH) Office of Compliance, Case for Quality Program Manager Francisco Vicenty commented, “The system works. It is as good as what you had before, and maybe better. That is what you are testing. You have confidence in it. You want to roll it out. I think I also heard you say something which I liked to hear mentioned, that you are focusing on the result it is trying to deliver, not predicting the non-conformance. That is not the goal. Non-conformances happen. My question is, why do we need to see anything else from a GMP standpoint? We should not be driving extra effort and behavior.”
Weese responded, “We have people who totally agree with you. And that is the pathway we would have probably gone down. But what you heard in this audience is exactly what we have heard frequently from other colleagues throughout this process.”
Another audience member asked if the results had been compared to the manual process output.
DiMartino responded that when user acceptance testing was completed, “for the most part we found it matched. There were one or two cases where we missed something. We will take a deep dive into those and understand what we can do to improve our tool.”
Another question dealt with the size of the investment to create the NLP tool and how the team convinced company management to make the investment.
DiMartino said the team pointed to three areas of savings or improvement when presenting the idea to company management. The first was the time spent on the manual process, which can be quantified. The second was the dollar value of reducing NCs across the network — for example, by 5 percent. The third, a non-quantitative one, was creating a better process and increasing compliance.
Weese referred to his earlier slide (see Amgen Quality Data Sciences Areas of Focus figure above). He said the eight bubbles “are somewhat sequential, and they build on each other. If we can get this to work correctly with deviations, then looking at safety incidents and things like that, it would use the same underlying platform we have already paid for.”
He said since the projects all rely on analysis of documents that are text-heavy, “if we get the text analysis correct, then it builds on itself as we go around my circle. The platforms are in place, so we do not need to re-invest in those same platforms. That is another part of the discussion with management.”
DiMartino added, “We did an analysis that sits on existing platforms. We did not have to buy software. There was still investment in time and resources to build it and there will be some to maintain it, but this is not a multimillion-dollar project.”
The dialogue on the use of AI in what has been termed “the fourth industrial revolution” — a fusion of technologies that is blurring the lines between the physical, digital, and biological spheres — will continue at the FDA/Xavier PharmaLink Conference in March 2019. Participants will be shown how some of the latest technological tools are being used to re-write how pharma manufacturing operations, quality systems, and supply chains are designed and executed.
About The Author:
 Jerry Chapman is a GMP consultant with nearly 40 years of experience in the pharmaceutical industry. His experience includes numerous positions in development, manufacturing, and quality at the plant, site, and corporate levels. He designed and implemented a comprehensive “GMP Intelligence” process at Eli Lilly and again as a consultant at a top-five animal health firm. Chapman served as senior editor at International Pharmaceutical Quality for six years and now consults on GMP intelligence and quality knowledge management and is a freelance writer. You can contact him via email, visit his website, or connect with him on LinkedIn.
Jerry Chapman is a GMP consultant with nearly 40 years of experience in the pharmaceutical industry. His experience includes numerous positions in development, manufacturing, and quality at the plant, site, and corporate levels. He designed and implemented a comprehensive “GMP Intelligence” process at Eli Lilly and again as a consultant at a top-five animal health firm. Chapman served as senior editor at International Pharmaceutical Quality for six years and now consults on GMP intelligence and quality knowledge management and is a freelance writer. You can contact him via email, visit his website, or connect with him on LinkedIn.